Alternative Fuel Technology Research Team
KIM Jeongyeong(Surveyor), KIM Sanghoon(Senior Surveyor)
KWON Jinwoo(Deputy Senior Surveyor), KANG Soomin(Senior Surveyor)
KIM Hakchan(Senior Surveyor)
1. Introduction
At the 80th session of the International Maritime Organization's (IMO) Marine Environment Protection Committee (MEPC), a goal was adopted to achieve net zero greenhouse gas (GHG) emissions from ships by 2050. To regulate the energy efficiency of existing vessels, the Marine Pollution Convention (MARPOL) was amended in 2023, introducing the Ship Energy Efficiency Index (EEXI) and the Carbon Intensity Indicator (CII) systems.
For new ships, the Energy Efficiency Design Index (EEDI) has been calculated based on the specifications of the ship from the construction stage. Existing ships must meet the permissible values of EEXI, calculated in the same manner as EEDI, and satisfy the annual reduction rate of the CII based on operational performance. In addition, existing ships are required to improve their annual CII by 2% each year from 2023 to 2026 compared to the 2019 baseline.
In response to these energy efficiency regulations, the maritime industries are exploring both immediate and medium-to long-term measures that can be applied to existing ships to enhance energy efficiency and reduce GHG emissions.
As the technological changes of the Fourth Industrial Revolution are demanded in the maritime industry, there is a shift towards digitalized ships based on the AI in operational management. Recent studies have focused on developing for predicting the emission of air pollutant (greenhouse gas, nitrogen oxide, particulate matter) from ships based on the AI models as a response to regulatory measures on emissions and environmental pollution.
These studies have explored the potential of the emission prediction using the time-series data through Deep Neural Networks (DNN) and Long Short-Term Memory (LSTM) models. As a result, the greenhouse gas prediction research based on AI can be proposed as a new development strategy for digitalized ships, and it is an essential component as the various energy efficiency improvement measures in the ship operation management.
In KR, the impact of lowering the temperature of the scavenge air cooling water on the fuel consumption was experimentally confirmed as a measure to improve the greenhouse gas emissions through improved the fuel consumption rates. It was observed that a decrease in the temperature of the scavenge air cooling water led to a reduction in the fuel consumption and the exhaust gas emission. Thus, it was confirmed that the temperature of the scavenge air cooling water is a factor that can improve energy efficiency and reduce the greenhouse gas emissions.
However, due to the physical limitations of the experimental environment, it was not possible to adjust the temperature of the scavenging air cooling water to the target of 10℃. This study developed an AI model which can predict the effect of improvements in the fuel consumption rate based on the temperature of the scavenging air cooling water, using experimentally acquired data, and want to share some of the results.
2. Prediction algorithm model and Data Preprocess
There are many different techniques for the prediction algorithm models such as Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Deep Neural Network (DNN).
In this study, the algorithm model used was the Long Short-Term Memory (LSTM) model, which has improved the issue in the RNN techniques and the strength of minimizing the gradient of the issue of time-series data. In addition, LSTM models can resolve the problem of long-term dependence, which makes it difficult to connect past information to current operations to optimize the model when training and predicting data. In the data learning process of this study, 1D CNN and LSTM were initially combined to reduce the data processing time. However, an increase in the prediction error rate was observed, leading to the decision to construct the prediction algorithm model using only LSTM layers.
The theory configuration of the LSTM model is shown in Figure 1. The basic structure consists of cells, which drive the overall learning, and gate, which decide what information to keep and drop as it learns. The cells save sequence data, and each gate uses an activation function, such as a sigmoid function and a hyperbolic tangent function.
The input gate is the gate for remembering current information, the forget gate is the gate for deciding whether to drop past information, and the output gate in the final gate that decides what the value to output. The theory construct of such an LSTM model is represented by the structure of the equations (1) to (6). Each formula uses the function shown in Figure 1 as a signal, which is then used to perform a mathematical calculation as data is input to create a final decision value.
𝑓𝑡=𝜎(𝑊𝑡∙[ℎ𝑡−1,𝑥𝑡]+𝑏𝑓) (1)
𝑖𝑡=𝜎(𝑊𝑖∙[ℎ𝑡−1,𝑥𝑡]+𝑏𝑖) (2)
𝐶̃𝑡=𝑡𝑎𝑛ℎ(𝑊𝑡∙[ℎ𝑡−1,𝑥𝑡]+𝑏𝑐) (3)
𝐶𝑡=𝑓𝑡 ∗𝐶𝑡−1+𝑖𝑡∗𝐶̃𝑡 (4)
𝑜𝑡=𝜎(𝑊𝑜∙[ℎ𝑡−1,𝑥𝑡]+𝑏0) (5)
ℎ𝑡=𝑜𝑡∗tanh(𝐶𝑡) (6)
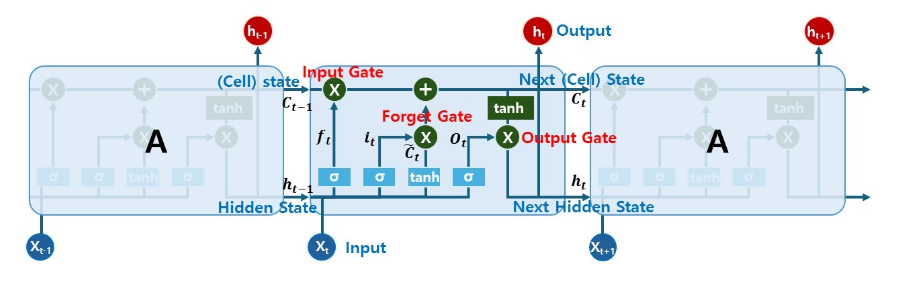
Figure 1. LSTM model internal structure
The database used for the prediction model used experimental data acquired by increasing the temperature to supply of the cooling water from 20°C to 45°C at 5°C intervals under 85% load operating conditions. To make effective use of the acquired time-series data, fuel consumption data, which is a direct factor in calculating the fuel consumption rate, was used. The experimental data was sampled at a 1Hz frequency, but it was determined that the amount of data was insufficient for the development of the prediction algorithm.
So, the resampling process was performed in the preprocessing stage to solve the insufficient data amount. However, the resampling process can be a low reliability for data and prediction model, so generating data in minimal amounts is being applied to improve accuracy.
As a result, the 1Hz data was generated with a sampling rate of 10Hz, and the missing values between the data were filled to the average value. Also, the 1Hz data and the 10Hz data generated in the preprocessing step were used to evaluate the accuracy of the prediction algorithm model.
3. Construction and Evaluation for Prediction Model
In this study, the prediction algorithm model was constructed using two LSTM layers to enhance memory retention capacity during the training process of the dataset. The model also included one dense layer to generate the final prediction output.
The model used the Adam Optimizer for optimization, with a learning rate set at 0.001. The batch size, which is the number of parameter updates for training, was set at 100, and the number of the training iterations (epochs) was set at 30. For training the data, 80% of the input data was used as the training dataset, 20% of the training data was used as the validation data, and another 20% of the input data was used as the test data.
Most learning models were trained with dropout to prevent overfitting to ensure proper learning, but it was not used in this prediction model as it was found to increase the error rates and decrease the prediction accuracy. Table 1 shows the training parameters for the constructed model. The first LSTM layer used 1,024 units with 60 neurons each, resulting in a parameter count of 4,202,496, and return_sequences, which returns the input neural network, is set to enabled (True).
The second LSTM layer used 1,024 units to increase the number of training parameters and the training volume. However, return_sequences parameter was set to false to enable the final output in the dense layer.
Layer(type) | Out Shape | Param # | Return_sequences |
LSTM | (None, 60, 1,024) | 4,202,496 | True |
LSTM | (None, 1,024) | 8,392,704 | False |
Dense | (None, 1) | 1,025 | - |
Table. 1 Parameters of the prediction algorithm model
The evaluation of the prediction models is difficult to express in terms of the accuracy values, so the algorithm is typically evaluated in terms of the error rate of the Root Mean Squared Error (RMSE) value. This can be expressed as the lower the error value, the higher the accuracy.
Therefore, in this study, the evaluation developed of the prediction algorithm models was expressed in terms of the RMSE values. The results of the training the prediction model using the fuel consumption data is shown in Figure 2. At 1Hz, it was confirmed that the training the RMSE value was learned from 0.05 to 0.003, and the validation RMSE value was learned from 0.01 to 0.0018.
At 10Hz, it was confirmed that the training RMSE value converges from 0.007 to 0, and the validation RMSE value mostly converges to 0. Accordingly, it was confirmed that the learning model produces the results with a low error rate when the sampling rate is high.
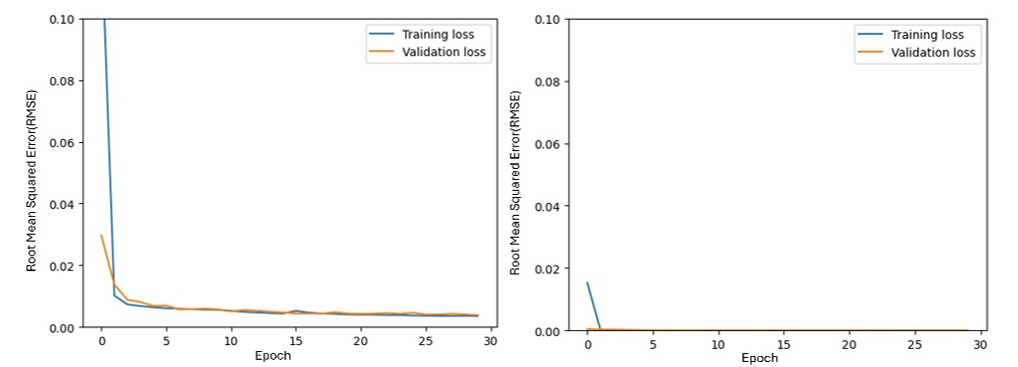
Figure 2. Train data learning results based on LSTM model (left: 1Hz, right: 10Hz)
The trained model performed the fuel consumption prediction using test data and the result is shown in Figure 3. The blue line represents the actual experimental fuel consumption data, the red line represents the predicted fuel consumption result value, this represents the fuel consumption value over time.
At 1Hz, it was confirmed that the prediction results are similar trend to the actual values, but the accuracy is lower. It was confirmed that the tendency and accuracy of the actual values and predicted results were high at 10Hz.
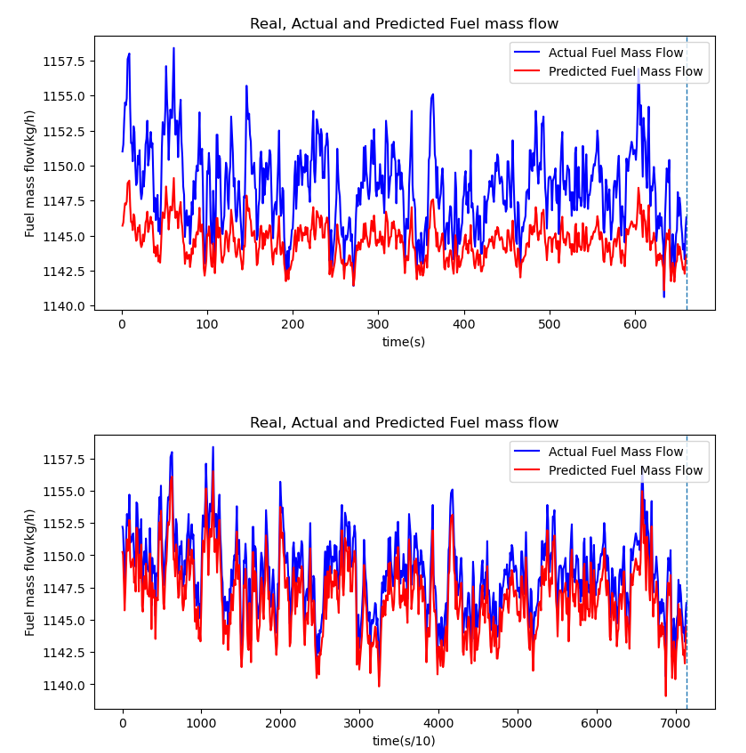
Figure 3. Test data prediction results based on LSTM model (top: 1Hz, down: 10Hz)
4. Conclusion
In this study, the fuel consumption prediction algorithm model based on a deep learning was developed to improve the energy efficiency of the ship two-stroke engines. The fuel consumption data according to the temperature of the scavenge cooling water was acquired from the test bed of the ship's two-stroke engine. To be able to evaluate model accuracy according to changes in sampling rate, resampling was performed from 1Hz to 10Hz.
The prediction algorithm using the LSTM model, a deep learning technique, and the learning evaluation was performed using the error rate of the RMSE value.
When the training data was learned using the algorithm model, learning was performed with a lower error rate at a sampling rate of 10Hz than at a sampling rate of 1Hz. This study analyzes that the accuracy of the prediction model can be improved if the sampling rate of data acquired through the real experiments is high.
On the other hand, it is analyzed that the accuracy of prediction can be improved by generating data with a high sampling rate from data with a low sampling rate through a resampling process. In the future, the developed algorithm model will be optimized with higher accuracy and use it to predict the fuel consumption rate for which experimental data is not available or requires data generation and the greenhouse gases, including exhaust gas.