替代燃料技术研究组
KIM Jeongyoung验船师, KIM Sanghoon责任
KWON Jinwoo先任, KANG Soomin责任, KIM Hakchan责任
1. 研究背景
国际海事组织(IMO)海洋环境保护委员会(MEPC)第80次会议通过了到2050年为止将船舶产生的GHG排放定为net zero的目标,为了限制现有船舶的能源效率,修改了《海洋污染防治公约》(MARPOL),从2023年开始引入船舶能源效率指数(EEXI)和碳密集度指数(CII)制度。
对于新造船,为了满足船舶能效设计指数(EEDI),从船舶建造阶段开始就以船舶的诸元为基础进行计算,现有船在满足与EEDI相同方法计算的EEXI允许值的同时,还必须满足每年根据运行业绩计算的年度CII缩减率。对于新造船,为了满足船舶能效设计指数(EEDI),从船舶建造阶段开始就以船舶的诸元为基础进行计算,现有船在满足与EEDI相同方法计算的EEXI允许值的同时,还必须满足每年根据运行业绩计算的年度CII缩减率。
此外,营运船应在2023年至2026年每年改善2%的年度CII,以应对2019年的标准。为了应对这种能源效率限制,造船、海运产业正在探索短期和中长期的应对方案,以立即适用于现有船舶的方案,以及改善能源效率和降低GHG排放量的技术。
随着第四次产业革命的技术变化在造船、海运产业也提出了要求,从航运管理的角度来看,正在向以人工智能为基础的数字化船舶转变,作为应对温室气体及环境污染物排放限制的方案,最近正在积极开展基于人工智能的温室气体产生量、氮氧化物排放量及细颗粒物浓度预测模型开发的研究。
在上述研究中,基于时间序列数据,利用Deep Neural Network(DNN)和Long Short-Term Memory(LSTM)模型确认了有关排放量预测的可能性。因此基于人工智能的温室气体预测相关研究可以作为数字化船舶的新开发方案提出,在船舶运行管理方面,不言而喻是多种能效改善应对方案所需的项目。
KR从船舶周期运营的角度出发,通过改善燃料消耗率来改善温室气体排放的方案,实验性地确认了扫气冷却水温度下调对燃料消耗率的影响。确认了随着扫气冷却水温度的降低,燃料消耗率减少,大气污染物排放也减少。也就是说,确认了扫气冷却水温度是可以改善能源效率和减少温室气体产生量的因子。
但由于实验环境的物理限制,无法将扫气冷却水温度调整到设定目标的10℃。对此本研究将以实验获得的数据为基础,开发人工智能模型,预测小气冷却水变化对燃料消耗率的改善效果,并共享部分成果。
2. 预测算法配置和数据前处理
预测算法模型有Convolutional Neural Network(CNN)、Recurrent Neural Network(RNN)、Deep Neural Network(DNN)等多种技术,但本研究使用了LSTM(Long Short-Term Memory)模型,其优点是改善了现有Recurrent Neural Network(RNN)技术的倾斜消失问题,最大限度地减少了获取的时间序列数据倾斜值的消失。
此外LSTM模型还可以解决长期依赖性问题,即在训练和预测数据时,为了优化模型,很难将过去的信息连接到当前任务。在本研究的数据学习过程中,为了减少数据处理时间,结合了1D CNN和LSTM,但发现预测误差率会提高,因此只利用LSTM layer来构造预测算法模型。
LSTM模型的理论组成如图1所示,基本结构由驱动进行整体学习的单元(Cell)和决定通过学习保留和丢弃哪些信息的门(Gate)组成。
单元格存储序列数据,每个门使用Sigmoid函数和超凸相切函数等激活函数。输入门(Input gate)是用来记住当前信息的门,遗忘门(Forget gate)是用来决定是否丢弃过去信息的门,输出门(Output gate)是决定输出什么值的最终门。
这种LSTM模型的理论组成用公式(1)~ (6)的结构表示。每个公式将利用图1中显示的函数作为信号形式,在输入数据时通过数学计算生成最终的决策值。
𝑓𝑡=𝜎(𝑊𝑡∙[ℎ𝑡−1,𝑥𝑡]+𝑏𝑓) (1)
𝑖𝑡=𝜎(𝑊𝑖∙[ℎ𝑡−1,𝑥𝑡]+𝑏𝑖) (2)
𝐶̃𝑡=𝑡𝑎𝑛ℎ(𝑊𝑡∙[ℎ𝑡−1,𝑥𝑡]+𝑏𝑐) (3)
𝐶𝑡=𝑓𝑡 ∗𝐶𝑡−1+𝑖𝑡∗𝐶̃𝑡 (4)
𝑜𝑡=𝜎(𝑊𝑜∙[ℎ𝑡−1,𝑥𝑡]+𝑏0) (5)
ℎ𝑡=𝑜𝑡∗tanh(𝐶𝑡) (6)
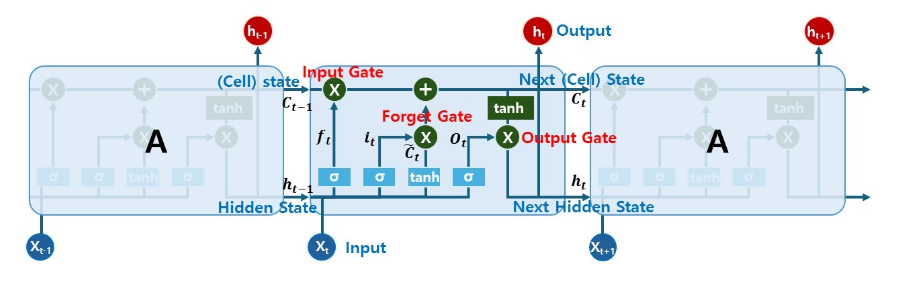
图1.LSTM型号内部结构
预测模型使用的数据库利用了在85%负荷运行条件下,将冷却水供应温度从20℃增加到45℃,间隔5℃获得的燃料消耗量数据。
为了积极利用通过实验获得的时间序列数据,本研究使用直接影响燃料消耗率计算的燃料消耗量数据开发了预测模型。实验数据以1Hz的周期采样,但为了开发预测算法,我们认为数据量会不足,因此在前处理阶段将执行重采样(Resampling)过程,以解决数据量不足的现象。
但是重新取样过程可能会降低对数据和预测模型的可靠性,因此以最少的量生成数据是提高准确度的方案。
因此将现有的1Hz数据生成为具有10Hz采样率的数据,并使用了将数据之间的检测值插值为平均值的方法。此外现有的1Hz数据和前处理阶段生成的10Hz数据用于评估预测算法模型的准确性。
3. 建立和评估预测模型
本研究构建的预测算法模型利用2个LSTM layer,在学习数据的训练过程中增加了记忆能力,并由1个dense layer组成,输出最终的预测结果。
模型优化使用了深度学习优化技术之一的Adam optimizer,将学习率(Learning rate)设置为0.001,将用于学习的参数更新数量(batchsize)设置为100,将数据集的学习次数Epoch设置为30。
为了学习数据,训练数据使用了输入数据的80%,验证数据使用了训练数据的20%,测试数据使用了输入数据的20%。大多数学习模型通过设置Drop out来学习,以应对过度拟合(Overfitting)以进行适当的学习,但在本研究的预测模型中,由于误差率提高,预测准确率下降,因此没有设置Drop out。
表1显示了所构建模型的学习参数。第一个LSTM layer使用1024个学习神经网络,每个学习神经网络60个,由此产生的参数数为4202496个,返回最后一个神经网络输出的返回序列(Return_seriences)设置为“使用”(True)值。
第二个LSTM layer神经网络使用1024个增加了学习参数的数量,增加了学习量,并将返回序列应用为未使用(False),以便在dense layer中进行最终输出。
Layer(type) | Out Shape | Param # | Return_sequences |
LSTM | (None, 60, 1,024) | 4,202,496 | True |
LSTM | (None, 1,024) | 8,392,704 | False |
Dense | (None, 1) | 1,025 | - |
表1. 预测模型参数
对预测模型的评价很难用准确度值来表示,所以一般都是用平均平方根误差(Root Mean Squared Error)值的误差率来评价算法。这可以用误差值越低准确度越高来表示,因此本研究构建的预测算法模型评价用平均平方根误差值来表示。
利用燃料消耗量数据的预测模型学习结果如图2所示。在1Hz下,训练平均平方根误差值从0.05学习到0.003,验证平均平方根误差值从0.01学习到0.0018。确认在10Hz时,训练平均平方根误差值从0.007收敛到0,验证平均平方根误差值大部分收敛到0。因此,验证了学习模型在采样率较高时出现误差率较低的结果。
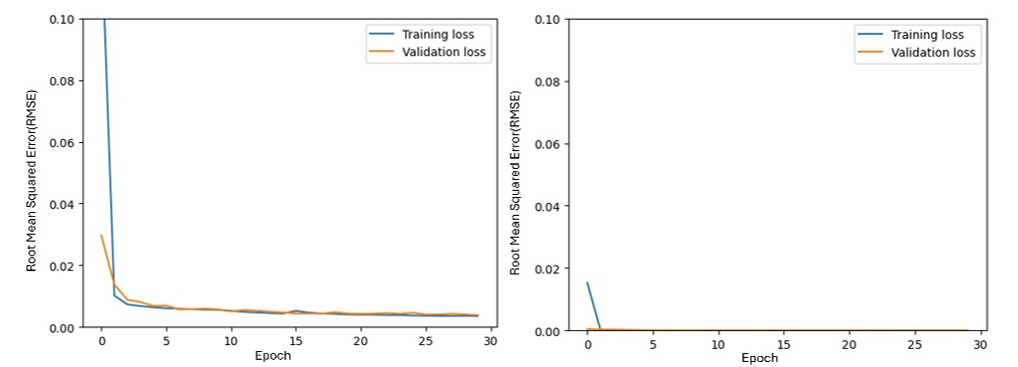
图2. 利用学习数据基于LSTM模型的学习结果(左:1Hz,右:10Hz)
完成学习的模型利用测试数据进行了燃料消耗量预测分析,如图3所示。蓝色实线是实际实验获取的燃油消耗量数据,红色实线表示对燃油消耗量数据进行预测的结果值,它表
示随时间的燃油消耗量值。在1Hz下,与实际值相比,预测结果的倾向性相似,但确认准确度较差。在10Hz时,确认实际值和预测结果的倾向性和准确度较高。
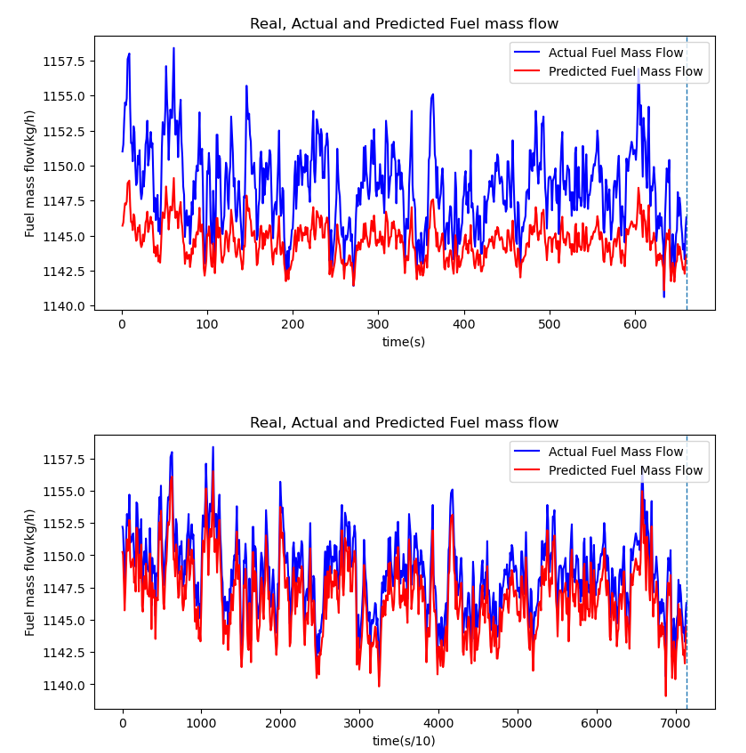
图3. 利用测试数据基于LSTM模型的预测结果(上:1Hz,下:10Hz)
4. 结论
本研究为改善船舶二冲程发动机的能效,开发了基于深度学习的燃油消耗量预测算法模型。
为此利用船舶二冲程发动机的测试平台,获取了所需冷却水温度下的燃油消耗量数据,并对其进行了1Hz至10Hz的再采样,以便根据采样率的变化评估模型准确度。预测算法利用了深度学习技术LSTM模型,并用平均平方根误差值进行学习评估。
当使用构建的模型学习训练数据时,确认在10 Hz时学习的误差率比采样率1 Hz时更低,在10 Hz时执行准确的预测。据分析如果通过实际实验获得的数据采样率高,可以提高预测模型的准确度。
相反分析认为如果将采样率较低的数据通过重采样过程生成具有较高采样率的数据进行预测将提高准确度。
今后构建的预测算法模型将优化为具有更高准确度的模型,用于对实验上无法获取数据或需要生成数据的燃料消耗率以及包括温室气体在内的大气污染物进行预测。