-
- KR Holds Internal AI Utilization Contest
- KR Holds “Eco-Friendly Technology Conference 2025”
- Technological and Collaborative Achievements at Gastech 2025
- KR Signs MOU to Promote Digital Transformation in the Maritime Industry
- KR Successfully Concludes Greece Technical Seminar and Roadshow
- KR Awards University Scholarships Totaling KRW 90 Million
-
- Notice for amendment of KR Technical Rules (Guidance on Strength Assessment of Container ships Considering the Whipping Effect)
- MSC110-News Final
- CCC11-News Flash
- Guidelines for approval of LSA Service Stations for servicing of Inflatable Life Saving Appliances & Procedure for approval of Competent Persons for servicing of such LSA
- Notice for amendment of KR Technical Rules (Rules/Guidance for the Classification of Steel Ships, Pt 1&Pt 8/Rules for the Classification of Ships Using LFF / Guidance for Approval of Service Suppliers)
- Revision of “Guideline of Structural Assessment for Liquefied Gas Carriers with Type A and B Prismatic Tanks”
- KR Holds Internal AI Utilization Contest
- KR Holds “Eco-Friendly Technology Conference 2025”
- Technological and Collaborative Achievements at Gastech 2025
- KR Signs MOU to Promote Digital Transformation in the Maritime Industry
- KR Successfully Concludes Greece Technical Seminar and Roadshow
- KR Awards University Scholarships Totaling KRW 90 Million
- Notice for amendment of KR Technical Rules (Guidance on Strength Assessment of Container ships Considering the Whipping Effect)
- MSC110-News Final
- CCC11-News Flash
- Guidelines for approval of LSA Service Stations for servicing of Inflatable Life Saving Appliances & Procedure for approval of Competent Persons for servicing of such LSA
- Notice for amendment of KR Technical Rules (Rules/Guidance for the Classification of Steel Ships, Pt 1&Pt 8/Rules for the Classification of Ships Using LFF / Guidance for Approval of Service Suppliers)
- Revision of “Guideline of Structural Assessment for Liquefied Gas Carriers with Type A and B Prismatic Tanks”
-
- KR Holds Internal AI Utilization Contest
- KR Holds “Eco-Friendly Technology Conference 2025”
- Technological and Collaborative Achievements at Gastech 2025
- KR Signs MOU to Promote Digital Transformation in the Maritime Industry
- KR Successfully Concludes Greece Technical Seminar and Roadshow
- KR Awards University Scholarships Totaling KRW 90 Million
-
- Notice for amendment of KR Technical Rules (Guidance on Strength Assessment of Container ships Considering the Whipping Effect)
- MSC110-News Final
- CCC11-News Flash
- Guidelines for approval of LSA Service Stations for servicing of Inflatable Life Saving Appliances & Procedure for approval of Competent Persons for servicing of such LSA
- Notice for amendment of KR Technical Rules (Rules/Guidance for the Classification of Steel Ships, Pt 1&Pt 8/Rules for the Classification of Ships Using LFF / Guidance for Approval of Service Suppliers)
- Revision of “Guideline of Structural Assessment for Liquefied Gas Carriers with Type A and B Prismatic Tanks”
PARK Jinyoung
Principal Surveyor of KR ICT Solution Team
1. Abstract
Establishing an optimal container stowage plan on a vessel is essential for ensuring both navigational safety and operational efficiency. In this study, we propose an artificial intelligence (AI)–based approach to container stowage optimization, moving beyond conventional heuristic methods traditionally used in planning. The proposed AI model interprets the stowage process as time-series data and is trained using a Long Short-Term Memory (LSTM) neural network. By applying a Multi-Task Learning (MTL) strategy, the model is designed to simultaneously predict multiple structural response variables. Furthermore, to enable deployment as an on-device AI system, the trained network was converted into the Open Neural Network Exchange (ONNX) format. This approach makes it possible to rapidly evaluate the structural stability of stowage configurations and propose optimized plans without resorting to complex computational analyses. This paper introduces the background of the technology, details of the model architecture, training methodology, and experimental results, and concludes with current limitations and directions for future work.
2. Introduction
With the advent of ultra-large container vessels, the number of tiers loaded above deck has increased, further amplifying the importance of safe and efficient stowage planning. The placement and sequencing of containers significantly influence the ship’s center of gravity, stability, and the distribution of loads on containers and lashing equipment. Therefore, finding the optimal stowage configuration is a key factor in determining both the safety of the vessel and its operational efficiency.
Currently, stowage planning is carried out by professional planners within shipping companies, who rely on their expertise combined with specialized software. During this process, multiple constraints must be considered, including vessel stability, cargo weight limits, and unloading sequences. However, traditional methods face inherent challenges: the number of possible combinations is enormous, leading planners to depend partly on experience and rule-based heuristics, while computational approaches often require repeated calculations to find acceptable solutions. Moreover, such methods struggle to respond dynamically in real time to changes such as plan modifications during loading operations or adverse weather conditions. This has driven recent interest in applying AI-based approaches that can adaptively learn and adjust optimal stowage strategies under varying conditions.
In parallel, international maritime regulations and classification society rules mandate the use of certified container lashing strength software. These tools calculate the forces acting on containers and securing devices under different loading conditions and verify compliance with allowable limits. For example, the Korean Register (KR) has developed tools such as SeaTrust-LS, which provides both structural safety assessments and capacity evaluations under given stowage plans. Nevertheless, identifying the optimal stowage configuration still requires extensive scenario-based calculations, which can be highly time-consuming. To overcome these limitations, research has recently focused on AI-driven approaches capable of learning from rule-based analysis results to improve efficiency in searching for optimal stowage solutions.
3. Background
The container stowage optimization problem has long been a central topic in research aimed at enhancing both operational efficiency and maritime safety. Traditionally, this problem has been approached through optimization techniques that rely heavily on repetitive calculations to obtain suitable solutions. Many of these methods improve upon an initially assumed stowage plan iteratively; however, they have notable limitations in handling dynamic scenarios such as mid-operation plan changes. Moreover, these methods often focus on container placement within a single bay, making it difficult to apply their results directly to the stowage of an entire vessel. At the same time, it is essential that any proposed stowage plan guarantees structural safety according to classification rules and regulations.
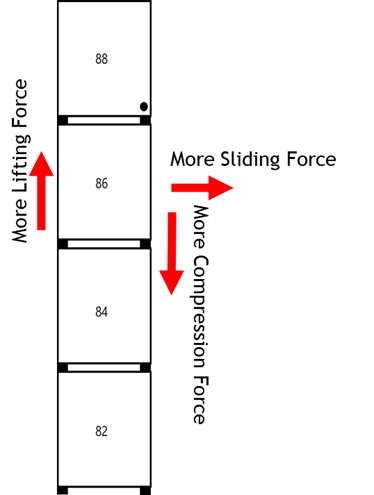
Figure 1. Loads on containers during Cargo Stowage
To perform such evaluations, container vessels are required to employ computational analysis tools—commonly referred to as lashing software—that calculate forces acting on containers and lashing systems during operation. These include racking, shear, lifting, and compression loads, which must be verified against permissible thresholds. For example, the SeaTrust-LS software developed by the Korean Register (KR) evaluates the loads on all container stacks for a given stowage condition and determines whether they exceed allowable limits. It also provides functionality to automatically compute maximum allowable capacities and suggest improved stowage strategies.
Although such rule-based software is capable of evaluating given stowage plans and achieving partial optimization, it remains impractical to exhaustively search the vast space of possible configurations. As a result, recent studies have sought to leverage artificial intelligence to learn and predict outcomes from rule-based analyses, thereby significantly improving the efficiency of exploring stowage solutions. This serves as the foundation and motivation for the present research.
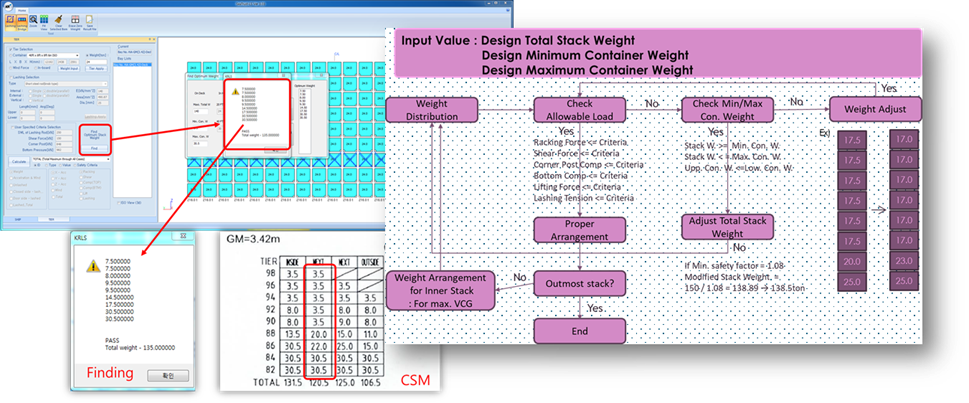
Figure 2. Conventional Iterative Calculation Method (in SeaTrust-LS)
4. Methodology
This project was carried out with the following objectives:
- To develop an AI-based algorithm for optimal container stowage using machine learning methods.
- To implement the developed algorithm in a deployable form that can be utilized in operational environments.
- To construct a learning model based on classification society rules.
- To realize an on-device AI agent capable of running on personal computers (Windows environments).
- To derive optimal stowage plans that reflect diverse design variables.
The core technical idea for achieving these goals was to treat the container loading process as sequential data, where containers are stacked one by one, and reformulate the problem as a time-series prediction task. This allows the model to retain memory of previously loaded containers and determine the most suitable position for each subsequent container. To this end, an LSTM (Long Short-Term Memory)–based model was adopted. LSTM, a type of recurrent neural network (RNN), is particularly well suited for learning long-term dependencies in time-series data.
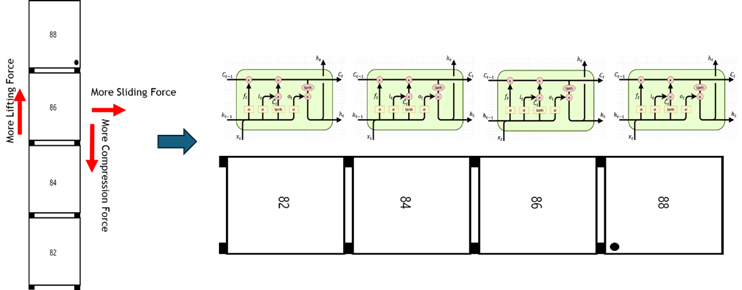
Figure 3. Application of LSTM Method
In this project, the LSTM was used to capture the cumulative effects of loading sequences, while Multi-Task Learning (MTL) was employed so that a single model could predict multiple target responses simultaneously. Specifically, the model was designed to output equivalent responses for several loading cases—such as racking, shear, lifting, and compression—through a single neural network.
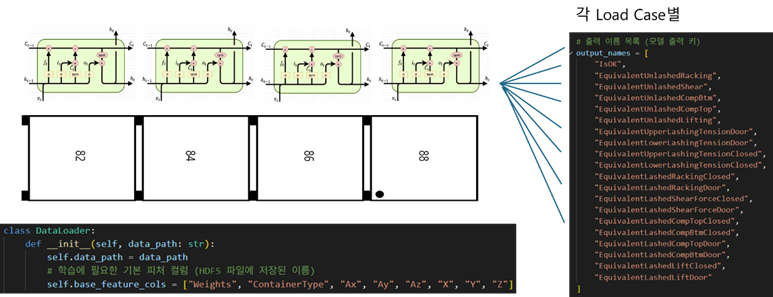
Figure 4. Application of LSTM + MTL
From an implementation standpoint, initial experiments applied classical machine learning algorithms such as decision trees and random forests. These were later replaced with deep neural networks (DNNs), and the MTL framework was incorporated to enhance predictive accuracy. However, due to the complex interdependencies inherent in container loading, the final model architecture was rebuilt around LSTM, combining it with the MTL approach. Training was performed in GPU environments to achieve optimal performance.
For model development, the Python-based TensorFlow framework was used. Upon completion of training, the model was converted into the ONNX (Open Neural Network Exchange) format, enabling deployment in C# environments. This ensured that the resulting AI model was both high-performing and practical for real-world applications.
LSTM (Long Short-Term Memory)
LSTM is a type of neural network architecture particularly effective for handling time-series data. It is capable of retaining information over extended periods, remembering critical features while discarding irrelevant ones. Typical applications include weather forecasting, stock price prediction, and early natural language processing tasks.
MTL (Multi-Task Learning)
Multi-Task Learning refers to the training of a single model to perform multiple tasks simultaneously. Much like a person learning both mathematics and English at the same time, the model acquires knowledge from various tasks in parallel, allowing for improved efficiency and generalization.
ONNX (Open Neural Network Exchange)
ONNX is a standardized format designed to store models created with different deep learning frameworks such as PyTorch and TensorFlow. It enables interoperability across platforms, making trained models portable and deployable in diverse environments.
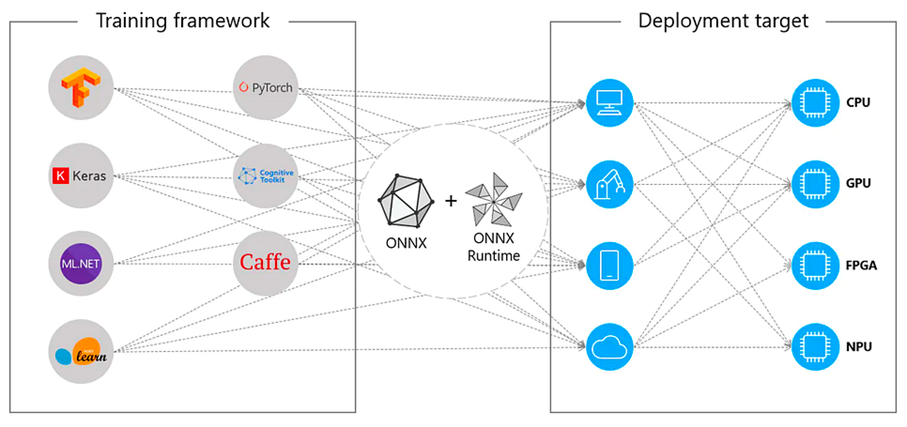
Figure 5. Concept of ONNX
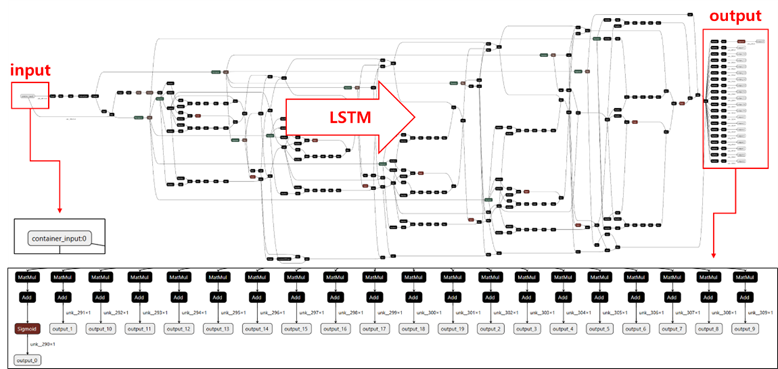
Figure 6. Learning Model (Structure of ONNX)
To generate the large-scale training data required for the AI model, the structural strength calculation module (SDK) of the Korean Register was utilized. By performing rule-based analyses across diverse stowage configurations, a comprehensive dataset of structural response values was compiled. After preprocessing, this dataset was used for training, ensuring adequate representation of complex design variables. Finally, the developed AI model was implemented as an API to allow easy user access and integrated into the SeaTrust-LS software for pilot testing.

Figure 7. Calculation Process
5. Model Architecture & Training
The input to the proposed AI model consists of the attributes of each newly loaded container—such as weight and dimensions—together with its designated stowage position (row, column, tier). These inputs are processed through a fully connected layer, which outputs a multi-dimensional prediction vector representing multiple target response values. In the final design, the model was configured with 18 output neurons, each corresponding to one of the principal structural responses considered under classification society rules. These included lateral racking, shear forces, upper and lower compression, tensile forces, and lashing tensions, ensuring comprehensive coverage of all load cases relevant to container stowage safety.
The training of the model was supervised using ground truth values generated by rule-based solvers. The loss function adopted was the Mean Squared Error (MSE), and errors across all outputs were aggregated with equal weighting, enabling simultaneous optimization under the Multi-Task Learning framework. The training dataset consisted of millions of stowage scenarios derived from rule-based analyses, with an 80/10/10 split allocated to training, validation, and testing, respectively, to ensure reliable generalization. During preprocessing, input variables were normalized to enhance training stability, while output values were scaled relative to their allowable thresholds to facilitate efficient learning.
Training was conducted in a GPU-accelerated environment using TensorFlow. The initial prototypes were lightweight models capable of running on CPUs; however, to handle the massive dataset required for final training, GPU memory optimization and batch training strategies were introduced. For efficient data handling, the datasets were converted into formats such as HDF5 to optimize input/output operations, and mini-batch feeding was employed to mitigate memory constraints.
To support integration into real-world operational environments, technical adaptations were also implemented. These included memory optimization during training, the use of socket-based communication for debugging interoperability between Python-TensorFlow and C# environments, and resolution of compatibility issues involving TensorFlow and CUDA versions. Upon completion, the trained model was exported in ONNX format to enable practical deployment as an on-device AI agent.

Figure 8. AI Model for On-device (ONNX)
To evaluate the predictive accuracy of the trained model, its outputs were compared against ground-truth results obtained from an independent test dataset. For one representative load case, the predicted responses were assessed against actual solver-calculated values using metrics such as Mean Squared Error (MSE) and Mean Absolute Error (MAE). The results demonstrated that, across most output categories, the MAE values ranged between 0.01 and 0.03, indicating a high level of accuracy. For instance, the MAE for unlashed racking was as low as 0.0123, while for lashed racking (door side) it remained at a reasonably acceptable level of 0.3175. Certain categories, however, showed relatively larger deviations, which were attributed to the greater variability and complexity of those load responses. It is expected that further improvements in predictive performance can be achieved by expanding the dataset and refining the model architecture.

Figure 9. Result of Learning
To assess the practical utility of the AI model, a case study was conducted by applying the model to real-world stowage scenarios. The predictions generated by the AI model for various container loading sequences were compared with results from the SeaTrust-LS software. The comparison confirmed that the AI-predicted responses were well aligned with the solver outputs across all examined categories.
In addition, the AI model was used to generate and evaluate multiple candidate stowage plans within seconds. These candidate plans were subsequently validated using conventional structural analysis software, confirming that the AI-recommended plans satisfied the requirements for structural safety and stability. Importantly, while traditional analysis workflows required several hours to evaluate hundreds of scenarios, the AI model was able to accomplish the same evaluation within seconds, drastically reducing computation time. This demonstrates the significant potential of the proposed approach for improving operational efficiency and supporting real-time decision-making in container stowage planning.
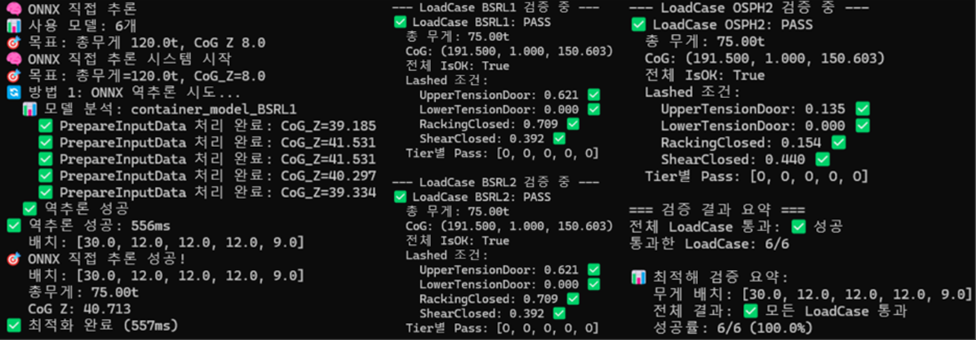
Figure 10. Example of Calculation (Inference)
7. Future Improvements
While the developed AI-based stowage optimization technology has demonstrated practical value, several limitations remain to be addressed, along with plans for future enhancement. The main issues are as follows:
Limitations in Data Generalization:
The model’s predictive performance is inherently dependent on the scope of its training data. As a result, its accuracy may decline under extreme stowage conditions or when applied to new vessel types with significantly different dimensions or loading capacities. To address this limitation, future work will involve expanding the diversity of training scenarios and, when necessary, employing techniques such as transfer learning to adapt the model to new environments.
System Integration and Performance Optimization:
Although the prototype model has been integrated with SeaTrust-LS through APIs and file-based modules, further improvements are needed for full-scale commercial deployment. Enhancements such as user-friendly interfaces and real-time data integration will be critical for practical adoption. In addition, the high computational demands of training highlight the need for model optimization and lightweight design. Techniques such as parameter tuning and pruning will be explored to reduce resource requirements while maintaining predictive accuracy.
By systematically addressing these areas, the AI-based stowage optimization framework can evolve into a more robust, scalable, and industry-ready solution.
8. Conclusion and Outlook
The on-device AI technology introduced in this study provides an efficient rule-based enhancement for solving the complex problem of container stowage planning. Compared to conventional methods, the proposed approach significantly improves the level of automation and efficiency in design processes. By training on millions of structural analysis datasets in advance, the deep learning model is capable of rapidly generating near-optimal stowage plans under similar conditions in practice. This not only ensures the safe navigation of container vessels but also enhances operational efficiency for shipping companies and terminal operations. Furthermore, it can support the decision-making process during shipbuilding by enabling quick evaluations of diverse design requirements.
Currently, the developed technology is undergoing pilot testing as a prototype feature within the SeaTrust-LS software. It is expected to be released in the future as a fully integrated product equipped with a user-friendly interface and additional functionalities.
Beyond its immediate application, the AI modeling and data utilization framework established in this research holds potential for broader extension to other optimization challenges within the shipbuilding and maritime industries.
Korean Register plans to continue advancing AI and big data technologies, positioning itself as a leader in digital innovation for the maritime sector, while providing reliable and trusted technical services to its customers.